|
Je nach Land / Region und Betriebssystem (DOS, UNIX, Windows) werden verschiedene Zeichensätze bzw. Zeichencodierungen für die Anzeige sowie Speicherung von Texten verwendet. Die Zeichenkodierungen sind teilweise untereinander nicht kompatibel. Insbesondere Sonderzeichen (z. B. Ä, Ü. Ö) werden bei einer anderen Zeichencodierung (oder einer anderen Länder-/Regionseinstellung) mit einem anderen Zeichen dargestellt. Einige Programme können verschiedene Zeichencodierungen anzeigen und speichern. In allen Linux-Distributionen ist ein kleines Programm enthalten, mit welchem sich ein Text oder eine Textdatei von einer gängigen Zeichencodierung in eine andere Codierung umwandeln lässt.
Hinweis: Das Programm ändert zwar die Zeichensatzkodierung, jedoch nicht die Art des Zeilenumbruchs (Unix / Windows). Hierzu kann nachfolgender Syntax verwendet werden:
- DOS-/Windows-Zeilenende zu Unix-Zeilenende: ""
- Unix-Zeilenende zu DOS-/Windows-Zeilenende: ""
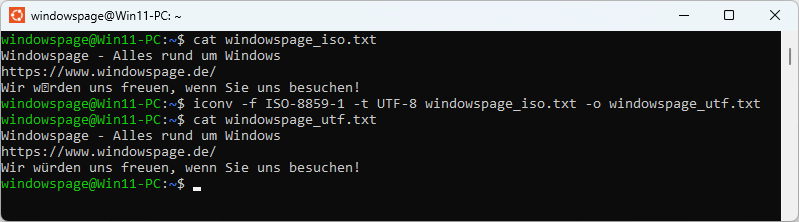
So geht's:
- Starten Sie die entsprechende Linux-Distribution (z. B. "" oder "").
- Als Befehl geben Sie den Syntax "" ein.
Z. B.: ""
- Drücken Sie die Eingabetaste.
- Die Zeichenkonvertierung wird durchgeführt.
Tabelle der Befehlsparameter (Auszug):
| Parameter |
Kurzbeschreibung |
| -c |
Alle Zeichen, die nicht umgewandelt werden können, werden verworfen. |
| -f [Quellkodierung] |
Die angegebene Quellkodierung für die Zeichen der Eingabe wird verwendet. |
| -l |
Listet alle bekannten / unterstützen Zeichensatzkodierungen auf. |
| -o [Ausgabedatei] |
Die angegebene Ausgabedatei für die Ausgabe wird verwendet. |
| -t [Zielkodierung] |
Die angegebene Zielkodierung für die Zeichen der Ausgabe wird verwendet. |
Tabelle der Kodierungen (Auszug):
| Kodierung |
Kurzbeschreibung |
| ASCII |
American Standard Code for Informaion Interchange |
| CP437 |
MS-DOS Englisch |
| CP850 |
MS-DOS Westeuropäisch |
| CP852 |
MS-DOS Mitteleuropäisch |
| CP858 |
MS-DOS Westeuropäisch mit Euro |
| CP860 |
MS-DOS Portugiesisch |
| CP865 |
MS-DOS Nordisch |
| CP866 |
MS-DOS Griechisch |
| IBM437 |
OEM United States |
| IBM850 |
DOS Westeuropäisch |
| IBM852 |
DOS Mitteleuropäisch |
| IBM1142 |
IBM EBCDIC (Deutsch mit Euro) |
| IBM1147 |
ICM EBCDIC (Französisch mit Euro) |
| ISO-8859-1 |
Latin-1, Westeuropäisch |
| ISO-8859-2 |
Latin-2, Mitteleuropäisch |
| ISO-8859-3 |
Latin-3, Südeuropäisch |
| ISO-8859-4 |
Latin-4, Nordeuropäisch |
| ISO-8859-15 |
Latin-9, Westeuropäisch |
| ISO-8859-16 |
Latin 10, Südosteuropäisch |
| UTF-7 |
Unicode (7-Bit) |
| UTF-8 |
Unicode (8-Bit) |
| UTF-16 |
Unicode (16 Bit) |
| UTF-32 |
Unicode (32 Bit) |
| Windows-1250 |
Windows Mitteleuropäisch |
| Windows-1252 |
Windows Westeuropäisch |
| [Kodierung]//IGNORE |
Wird die Zeichenkette an die Zielkodierung angehängt, dann werden nicht umwandelbare Zeichen verworfen. |
| [Kodierung]//TRANSLIT |
Wird die Zeichenkette an die Zielkodierung angehängt, dann werden die Zeichen umgeschrieben. Zeichen die nicht umgeschrieben werden können, werden mit einem Fragezeichen (?) ausgegeben. |
Beispiele:
- Die Datei "windowspage_utf.txt" von UTF-8 in ASCII umwandeln, falls notwendig, Zeichen umschreiben und als "windowspage_ascii.txt" speichern:
""
- Die Datei "windowspage_utf.txt" von UTF-8 in die DOS-Codepage 850 umwandeln, alle nicht umwandelbaren Zeichen verwerfen und als "windowspage_850.txt" speichern:
""
- Alle Kodierungen (inkl. Aliasnamen) ausgeben:
""
Hinweis:
- Weitere Optionen zur Textbearbeitung können mit dem Befehl "" ausgegeben werden.
Versionshinweis:
- Die Linux-Distributionen benötigen mindestens Windows 10 Version 1703.
|